Refactoring Databases — Scott Ambler
pdf-download epub-downloadMartin Fowler [1] describes refactoring as a disciplined way to restructure code in small steps. Refactoring enables you to evolve your code slowly over time and thereby take an evolutionary (iterative and incremental) approach to programming. A critical aspect of a refactoring is that it retains the behavioral semantics of your code. You do not add functionality when you are refactoring, nor do you take it away. A refactoring merely improves the design of your code – nothing more and nothing less.
Similarly, a database refactoring [2, 3] is a simple change to a database schema that improves its design while retaining both its behavioral and informational semantics – in other words, you cannot add new functionality or break existing functionality, nor can you add new data or change the meaning of existing data. A database schema includes both structural aspects, such as table and view definitions, and functional aspects, such as stored procedures and triggers. I use the terms code refactoring to refer to traditional refactoring as described by Martin Fowler and database refactoring to refer to the refactoring of database schemas. The process of database refactoring is the act of making these simple changes to your database schema.
Informational semantics refers to the meaning of the information within the database, from the point of view of the users of that information. Preserving the informational semantics implies that if you change the values of the data stored in a column, the clients of that information should not be affected by the change – for example, if you apply the Introduce Common Format database refactoring to a character-based phone number column to transform data such as (416) 555-1234 and 905.555.1212 into 4165551234 and 9055551212, respectively. Although the format has been improved, requiring simpler code to work with the data, from a practical point of view the true information content has not. Note that you would still choose to display phone numbers in (XXX) XXX-XXXX format, you just would not store the information in that manner.
When preserving behavioral semantics the goal is to keep the black-box functionality the same – any source code that works with the changed aspects of your database schema must be reworked to accomplish the same functionality as before. For example, if you apply Introduce Calculation Method, you may want to rework other existing stored procedures to invoke that method rather than implement the same logic for that calculation. Overall, your database still implements the same logic, but now the calculation logic is just in one place.
Database Refactoring - Key Points
- Database refactoring is a simple change to your database schema that improves the design without changing the semantics.
- Database refactoring is one of several techniques which enable data professionals to work in an evolutionary manner.
- Due to high-levels of coupling within your data architecture, you will require a transition period during which you support both the old and new schemas.
- You need a database regression test suite in place to support database refactoring.
- Few data management organizations currently have coherent strategies for fixing legacy data or effective database testing in place. Sadly, few have even thought of the ideas.
- Just as the agile community has raised the bar for quality in application development, now we're raising the bar for data management.
Why Database Refactoring?
When I speak about database refactoring, and agile database techniques in general, at conferences I always like to get the audience thinking outside of the box. I do this by asking a collection of fairly straightforward questions and asking for a show of hands. Three of my favorite questions are “Do any of you work in organizations where you have perfect data sources?”, “If I was to ask you to go back to your organization tomorrow and rename a column in the most important table in your production database, could you successfully do so in less than a day?” and “Do you have application development teams going around your data group and doing the database design by themselves?”.
The audience will usually laugh at the first question, and frankly I’ve never seen anyone answer yes to it. I then ask the follow-up question “Do any of your organizations have a viable strategy for addressing your data-oriented problems, other than trying to make sure it doesn’t get any worse?” and very rarely does a hand go up.I then point out that the strategy of making sure things don’t get worse is a losing strategy because all it takes is one team to put in yet another silo database and the situation has grown. I can usually hear a pin drop after stating this. Clearly there are some serious problems out there in data land.
Laughter is also usually the reaction to the second question, particularly when there are many people in the audience working in large organizations, although I sometimes there are people in the audience who answer in the affirmative. This is either because they work in small organizations with few applications or database access is encapsulated; in either case renaming a column is a relatively trivial task. The people who laugh know that if they were to attempt such a thing they would break numerous applications. Sadly, they have no expectation of their data management group even being able to accomplish a trivial task such as renaming a column, let alone doing something that could actually add value to your organization. Although it may seem that I’m being a bit unfair to the data management folks out there, as far as I’m concerned if they want to be in that role then they need to be responsible for actually fulfilling its responsibilities. Worse yet, as I’ll show you in this article, it is in fact possible to rename a column in a production database even when hundreds of heterogeneous applications are coupled to it.
The third question usually results in the majority of the audience saying yes, once again particularly so when there are many people from large organizations. I will often ask a follow-up question such as “And do the developers do a less-than-perfect job of the database design?” which often gets people laughing. After doing so, I usually see a few smug looks on some faces, so then I ask “And how many of you work in organizations that give developers the training that they need to do the database design properly?” they’re often not smirking anymore. I suspect that the reason why developers avoid working with the data management groups in their organizations is that they find them too difficult to work with, or simply too slow. At the Software Development 2006 conference Dagna Gaythorpe, a well-respected data professional, started one of her talks with the joke “When you walk up to a data professional, before you can say a thing they blurt out ‘It’ll take 3 months, now what’s the question?’”. Although this is obviously an exaggeration, it isn’t too far off the mark within many organizations.
The answers to these questions reveal two fundamental reasons why you want to be able to refactor your databases:
- To repair existing legacy databases [Ed’s note: Michael Feather’s “working with legacy code” is also contained in this issue]. Database refactoring enables you to safely evolve your database design in small steps, making it an important technique for improving the legacy assets within your organization This is much less risky than a “big bang” approach where you rewrite all of your applications and rework your database schema and release them all into production at once. It is much better than the “let’s try not to allow things to get any worse” strategy currently employed by most data management groups.
- To support evolutionary software development. Modern software development processes, including the Rational Unified Process (RUP), Extreme Programming (XP), Agile Unified Process (AUP), Scrum, and Dynamic System Development Method (DSDM), are all evolutionary in nature. Craig Larman [4] summarizes the research evidence, as well as the overwhelming support among the thought leaders within the IT community, in support of evolutionary approaches. Unfortunately, most data-oriented techniques are serial in nature, relying on specialists performing relatively narrow tasks, such as logical data modeling or physical data modeling. Therein lies the rub – the two groups need to work together, but both want to do so in different manners. I believe that data professionals need to adopt evolutionary techniques, such as database refactoring, which enable them to be relevant to modern development teams. Luckily these techniques exist [3], and they work quite well, it is now up to data professionals to choose to adopt them.
Example Database Refactorings
- Add Foreign Key Constraint. Add a foreign key constraint to an existing table to enforce a relationship to another table.
- Apply Standard Codes. Apply a standard set of code values to a single column to ensure that it conforms to the values of similar columns stored elsewhere in the database.
- Introduce Calculation Method. Introduce a new method, typically a stored function, which implements a calculation that uses data stored within the database.
- Migrate Method to Database. Rehost existing application logic in the database.
- Move Column. Migrate a table column, with all of its data, to another existing table.
- Replace One-To-Many with Associative Table. Replace a one-to-many association between two tables with an associative table.
- Use Official Data Source. Use the official data source for a given entity, instead of the current one which you are using.
Implementing a Database Refactoring
Database refactorings are conceptually more difficult than code refactorings: Code refactorings only need to maintain behavioral semantics, whereas database refactorings must also maintain informational semantics. Worse yet, database refactorings can become more complicated by the amount of coupling resulting from your database architecture. Coupling is a measure of the dependence between two items; the more highly coupled two things are, the greater the chance that a change in one will require a change in another.
Some project teams find themselves in a relatively simple, “single-application database” architecture, and if so they should consider themselves lucky because database refactoring is fairly easy in that situation – you merely change your database schema and update your application to use the new version of the schema. I never seem to work in situations like this, but they’re rumored to exist so I thought I’d mention them.
What is more typical is to have many external programs interacting with your database, some of which are beyond the scope of your control. In this situation you cannot assume that all the external programs will be deployed at once, and must therefore support a transition period during which both the old schema and the new schema are supported in parallel. This situation is more difficult because the individual applications will have new releases deployed at different times over the next year and a half. Figure 1 depicts a UML 2 Activity diagram that overviews the database refactoring process [3].
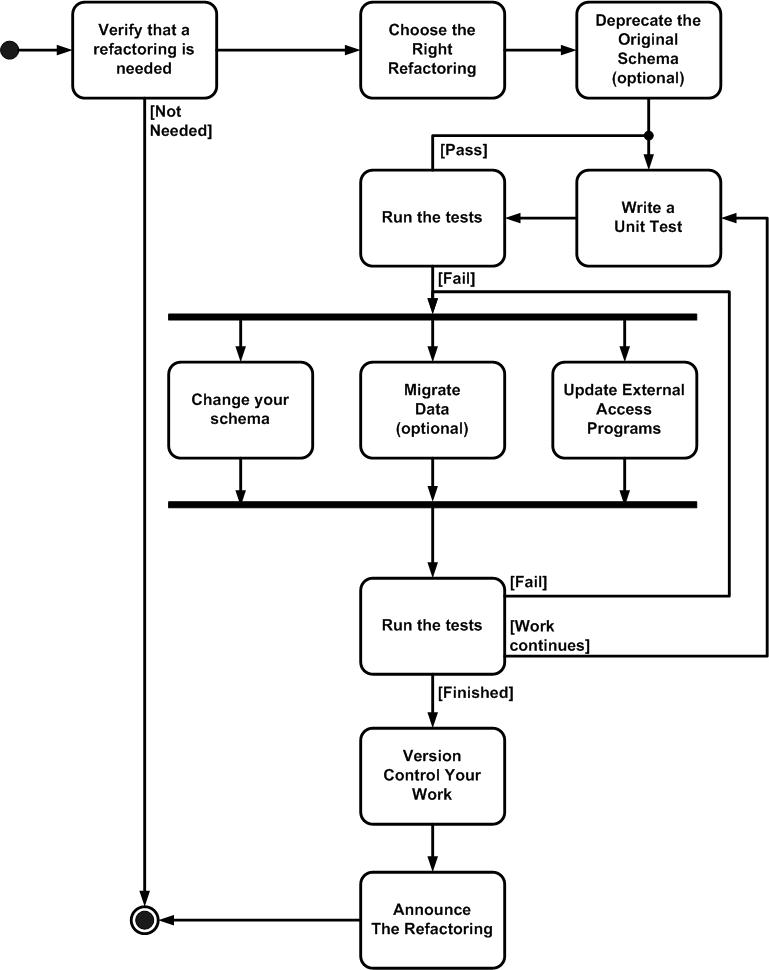
Figure 1. The database refactoring process
To put database refactoring into context, let's step through a quick example. You are about to implement a new requirement which involves working with the first names of customers. You look at the existing database schema for the Customer table, depicted in Figure 2 , and realize that the column name isn’t easy to understand. You decide to apply the Rename Column refactoring to the FName column to rename it to FirstName so that the database design is the best one possible which allows you to implement the new requirement.
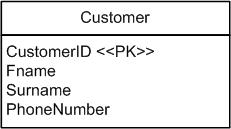
Figure 2. The initial database schema for Customer.
Agilists typically work together as a pair; one person should have application programming skills, the other database development skills, and ideally both people have both sets of skills. This pair begins by determining whether the database schema needs to be refactored. Perhaps the programmer is mistaken about the need to evolve the schema, and how best to go about the refactoring. The refactoring is first developed and tested within the developer's sandbox. When it is finished, the changes are promoted into the project-integration environment, and the system is rebuilt, tested, and fixed as needed.
To apply the Rename Column refactoring in the development sandbox, the pair first runs all the tests to see that they pass. Next, they write a test because they are taking a Test-Driven Design (TDD) approach [5, 6, 7]. A likely test is to access a value in the FirstName column.
After running the test and seeing it fail, they implement the actual refactoring. To do this they introduce the FirstName column and the SynchronizeFirstName trigger as you see in Figure 3, and the Oracle code to do this follows. Due to a lack of tooling at the time of this writing, this code would be captured as a single “change script”.

Figure 3. The database schema during the transition period.
The trigger is required to keep the values in the columns synchronized – each external program accessing the Customer table will at most work with one but not both columns. At first, all production applications will work with FName, but over time they will be reworked to access FirstName instead. There are other options to do this, such as views or synchronization after the fact, but I find that triggers work best
ALTER TABLE Customer ADD FirstName VARCHAR(40);
COMMENT ON Customer.FirstName ‘Renaming of FName column, finaldate = November 14 2007’;
COMMENT ON Customer.FName ‘Renamed to FirstName, dropdate = November 14 2007’;
UPDATE Customer SET FirstName = FName;
CREATE OR REPLACE TRIGGER SynchronizeFirstName
BEFORE INSERT OR UPDATE
ON Customer
REFERENCING OLD AS OLD NEW AS NEW
FOR EACH ROW
DECLARE
BEGIN
IF INSERTING THEN
IF :NEW.FirstName IS NULL THEN
:NEW.FirstName := :NEW.FName;
END IF;
IF :NEW.Fname IS NULL THEN
:NEW.FName := :NEW.FirstName;
END IF;
END IF;
IF UPDATING THEN
IF NOT(:NEW.FirstName=:OLD.FirstName) THEN
:NEW.FName:=:NEW.FirstName;
END IF;
IF NOT(:NEW.FName=:OLD.FName) THEN
:NEW.FirstName:=:NEW.FName;
END IF;
END IF;
END;
The FirstName column must be populated with values from the FName column. The easiest way to do this is to simply run the following SQL code. This code would be captured as single script referred to as a “migration script”.
UPDATE Customer SET FirstName = FName;
You need to run both columns, FName and FirstName, in parallel during a transition period of sufficient length to give the development teams time to update and redeploy all of their applications. This transition period could be several years in length, depending on the ability of your project teams to get new releases into production. In this case we’ve decided that the transition period will run to November 14, 2007 (roughly 1.5 years in this case).
The pair rerun the test suite and see that the tests now pass. They then refactor the existing tests, to work with the FirstName column rather than the FName column. Once the database refactoring is completed in their development work environment, the pair promotes their work into the team’s integration sandbox where they rebuild and rerun the tests, fixing any problems which they find. To update the database schema, the pair runs the appropriate change and migration scripts in the appropriate order.
This promotion strategy continues into a pre-production integration testing environment and then eventually into production. Depending on your need, you could implement and then deploy the refactoring within a single day, although more realistically it would be several months until the next major release of your application and at that point you would deploy the refactoring along with any other updates that you’ve made.
After the transition period, you remove the original column plus the trigger(s), resulting in the final database schema of Figure 4. The Oracle code to do this is shown below, which would be captured in a “transistion script”. You remove these things only after sufficient testing to ensure that it is safe to do so. At this point, your refactoring is complete.
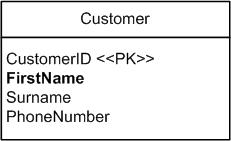
Figure 4. The final database schema for Customer.
--On or following Nov 14 2007 DROP TRIGGER
DROP TRIGGER SynchronizeFirstName; ALTER TABLE Customer DROP COLUMN FName;
There is a little bit more to successfully implementing a database refactoring than what I’ve described. You need a way to coordinate the refactoring efforts of all the development teams within your organization, clearly something that may prove quite difficult. You also need to get good at deploying refactorings in production, once again coordinating the efforts of several teams. In Refactoring Databases [3], my co-author Pramod Sadalage and I discuss several strategies for doing these things.
Database Refactoring and Testing
You can have the confidence to change your database schema only if you can easily validate that the database still works with your application after the change, and the only way to do that is to take a TDD-based approach where you write a test and then you write just enough code to fulfill the test. You continue in this manner until the database refactoring has been implemented fully. You will potentially need to write tests that:
- Test your database schema. You can validate many aspects of a database schema: Stored procedures and triggers, referential integrity (RI) rules, view definitions, default value constraints, and data invariants [8].
- Test the way your application uses the database schema. Your database is accessed by one or more programs, including the application that you are working on. These programs should be validated just like any other IT asset within your organization.
- Validate your data migration. Many database refactorings require you to migrate and sometimes even cleanse the source data. In our example, we must copied the data values from FName to FirstName as part of implementing the refactoring.
Why Not Just Get it Right to Begin With?
I am often told by existing data professionals that the real solution is to model everything up front, and then you would not need to refactor your database schema. Although that is an interesting vision, and I have seen it work in a few rare situations, experience from the past three decades has shown that this approach does not seem to be working well in practice for the overall IT community [Editor’s note: see Ed Yourdon’s retrospective on Structured Analysis in this issue]. The traditional approach to data modeling does not reflect the evolutionary approach of modern methods such as the RUP and XP, nor does it reflect the fact that business customers are demanding new features and changes to existing functionality at an accelerating rate. The old ways simply aren’t sufficient any more, if they ever were [11].
I suggest that you take an Agile Model-Driven Development (AMDD) approach [9, 10], in which you do some high-level modeling to identify the overall "landscape" of your system, and then model storm the details on a just-in-time (JIT) basis. You should take advantage of the benefits of modeling without suffering from the costs of over-modeling, over-documentation, and the resulting bureaucracy of trying to keep too many artifacts up-to-date and synchronized with one another. Your application code and your database schema evolve as your understanding of the problem domain evolves, and you maintain quality through refactoring both.
AMDD is different than traditional Model Driven Development (MDD), exemplified by the Object Management Group (OMG)’s Model Driven Architecture (MDA) standard (www.omg.org) , in that it doesn’t require you to create highly-detailed, formal models. Instead, AMDD is a streamlined approach to development that reflects agile software development values and principles, providingway to create artifacts such as physical data models that are critical to the success of agile DBAs. The collaborative environment fostered by AMDD promotes communication and cooperation between everyone involved on your project. This helps to break down some of the traditional barriers between groups in your organization and to motivate all developers to learn and apply the wide range of artifacts required to create modern software – there’s more to modeling than data models.
In Conclusion
Database refactoring is a database implementation technique, just like code refactoring is an application implementation technique. You refactor your database schema to ease additions to it. You often find that you have to add a new feature to a database, such as a new column or stored procedure, but the existing design is not the best one possible to easily support that new feature. You start by refactoring your database schema to make it easier to add the feature, and after the refactoring has been successfully applied, you then add the feature. The advantage of this approach is that you are slowly, but constantly, improving the quality of your database design. This process not only makes your database easier to understand and use, it also makes it easier to evolve over time; in other words, you improve your overall development productivity.
My experience is that data professionals can benefit from adopting modern evolutionary techniques similar to those of developers, and that database refactoring is one of several important skills that data professionals require. Unfortunately, the data community missed the object revolution of the 1990s, which means they missed out on opportunities to learn the evolutionary techniques that application programmers now take for granted. In many ways, the data community is also missing out on the agile revolution, which takes evolutionary development one step further to make it highly collaborative and cooperative.
References
- Fowler, M. (1999). Refactoring: Improving the Design of Existing Code. Menlo Park, California: Addison Wesley Longman, Inc.
- Ambler, S.W. (2003). Agile Database Techniques: Effective Strategies for the Agile Software Developer. New York: John Wiley & Sons. http://www.ambysoft.com/books/agileDatabaseTechniques.html
- Ambler, S.W. and Sadalage, P.J. (2006). Refactoring Databases: Evolutionary Database Design. Boston: Addison Wesley. http://www.ambysoft.com/books/refactoringDatabases.html
- Larman, C. (2004). Agile and Iterative Development: A Manager’s Guide. Boston: Addison-Wesley.
- Astels D. (2003). Test Driven Development: A Practical Guide. Upper Saddle River, NJ: Prentice Hall.
- Beck, K. (2003). Test Driven Development: By Example. Boston, MA: Addison Wesley.
- Ambler, S.W. (2004c). Introduction to Test Driven Development (TDD). http://www.agiledata.org/essays/tdd.html
- Ambler, S.W. (2006a). A Roadmap for Regression Testing Relational Databases. http://www.agiledata.org/essays/databaseTesting.html
- Ambler, S.W. (2002). Agile Modeling: Best Practices for the Unified Process and Extreme Programming. New York: John Wiley & Sons. http://www.ambysoft.com/books/agileModeling.html
- Ambler, S.W. Agile Model Driven Development (AMDD). http://www.agilemodeling.com/essays/amdd.htm
- The Agile Data Home Page. http://www.agiledata.org/